
Hadoop چیست؟ + مزایا و معایب و کاربردهای هدوپ

هدوپ یا Hadoop یک فریم ورک محاسباتی توزیع شده می باشد که در جهت ذخیره و پردازش حجم عظیمی از داده ها استفاده می شود. این فریم ورک برای مقابله با چالش های مدیریت و تجزیه و تحلیل کلان داده هایی طراحی شده است که پایگاه های داده سنتی و ابزارهای پردازش داده برای رسیدگی به آنها مجهز نیستند. به طور کلی، Hadoop به سازمان ها اجازه می دهد تا مجموعه داده های بزرگ (Big Data) را به روشی مقرون به صرفه، مقیاس پذیر و کارآمد ذخیره، پردازش، تجزیه و تحلیل کنند.
در این مقاله، تاریخچه و اجزای اصلی Hadoop، نحوه عملکرد، کاربرد ها، مزایا و محدودیت های آن و همچنین آینده این فناوری نوآورانه را بررسی خواهیم کرد. در پایان این مقاله، درک بهتری از چیستی Hadoop و چرایی اهمیت آن برای مشاغل مدرن خواهید داشت. همراه ما باشید.
Hadoop چیست؟
Hadoop یک سیستم نرم افزاری رایگان می باشد که داده های بزرگ را در چندین رایانه ذخیره و پردازش می کند. این فریمورک در سال 2005 توسط داگ کاتینگ (Doug Cutting) و مایک کافرلا (Mike Cafarella) ساخته شد و توسط بنیاد نرم افزار آپاچی (Apache) مدیریت می شود. هدوپ می تواند انواع مختلفی از داده ها را مدیریت کند، چه ساختار یافته و چه بدون ساختار.
![]()
تاریخچه Hadoop
Hadoop از مدل های MapReduce Google و Google File System (GFS) الهام گرفته شده است؛ مدل هایی که روشی را برای پردازش مجموعه داده های بزرگ در میان خوشه های سخت افزار کالا توضیح می دهد. داگ کاتینگ که در آن زمان در یاهو کار می کرد، یک پیاده سازی متن باز از این ایده ها ایجاد کرد و نام فیل اسباب بازی پسرش که Hadoop بود را روی آن گذاشت. هدوپ به سرعت محبوبیت پیدا کرد و اکنون به طور گسترده در بسیاری از صنایع از جمله مدیریت مالی، مراقبت های بهداشتی و مخابرات استفاده می شود.
اجزای اصلی Hadoop
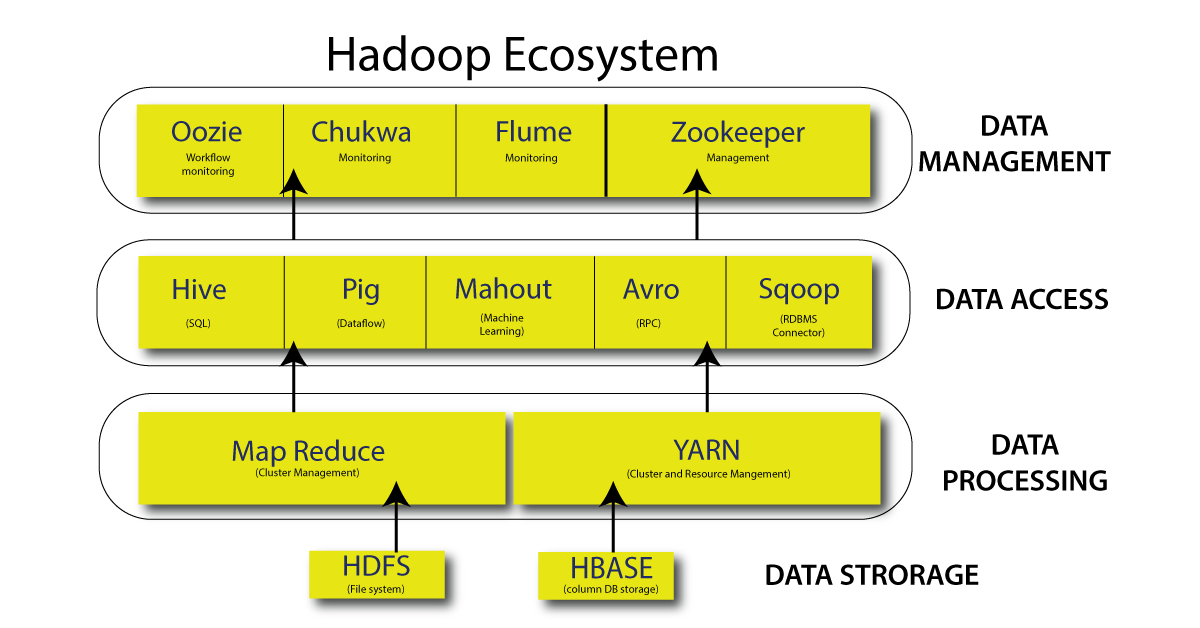
هدوپ از 4 جزء اصلی تشکیل شده است که در ادامه به توضیح هر یک از این اجزا می پردازیم:
1- Hadoop Distributed File System (HDFS)
HDFS یک سیستم فایل توزیع شده است که دسترسی با توان بالا به داده ها را در چندین گره یک خوشه هدوپ فراهم می کند. این سیستم برای ذخیره مجموعه داده های بزرگ، با شکستن آنها به بلوک ها و توزیع شان در چندین گره، به طور مطمئن و کارآمد طراحی شده است. HDFS در برابر خطا ها مقاوم می باشد و می تواند با تکثیر داده ها در چندین گره، خرابی گره ها را مدیریت کند.
2- Yet Another Resource Negotiator (YARN)
YARN یک سیستم مدیریت منابع می باشد که منابع را در یک خوشه Hadoop مدیریت می کند. این سیستم مسئول تخصیص منابع به برنامه ها و زمان بندی وظایف در گره های خوشه است. YARN به چندین برنامه اجازه می دهد تا روی یک خوشه اجرا شوند و همچنین، فریمورکی برای ساخت برنامه های کاربردی توزیع شده فراهم می کند.
3- MapReduce
MapReduce یک مدل برنامه نویسی برای پردازش مجموعه داده های بزرگ در چندین گره یک خوشه هدوپ است. این مدل شامل دو مرحله می باشد: نقشه (Map) و کاهش (Reduce). در مرحله نقشه، داده ها پردازش و فیلتر می شوند تا مجموعه ای از جفت های کلید-مقدار تولید شوند. در فاز کاهش، جفت های کلید-مقدار جمع می شوند تا خروجی نهایی بدست بیاید.
4- Common Utilities
کتابخانه های رایج جاوا را ارائه می دهد که می توانند در همه ماژول ها استفاده شوند.
مقایسه Hadoop با پایگاه داده های سنتی
Hadoop از چندین جهت با پایگاه داده های سنتی متفاوت می باشد. اول از همه، هدوپ برای مدیریت مجموعه داده های بزرگ و بدون ساختار طراحی شده است، در حالی که پایگاه داده های سنتی برای داده های ساخت یافته بهینه شده اند. دوم، Hadoop برای اجرا بر روی سخت افزار کالا طراحی شده، در حالی که پایگاه داده های سنتی اغلب به سخت افزار گران قیمت و نرم افزار تخصصی نیاز دارند. در نهایت، هدوپ برای پردازش دسته ای طراحی شده است، در حالی که پایگاه داده های سنتی برای پردازش تراکنش های بلادرنگ بهینه شده اند.
به طور کلی، Hadoop یک فریمورک قدرتمند و انعطاف پذیر برای ذخیره و پردازش مجموعه داده های بزرگ ارائه می کند که همین ویژگی، آن را به ابزاری ضروری برای کسب و کار های مبتنی بر داده های مدرن تبدیل کرده است.
Hadoop چگونه کار می کند؟
معماری Hadoop
معماری هدوپ از اجزای متعددی تشکیل شده است که با یکدیگر کار می کنند تا حجم زیادی از داده را ذخیره و پردازش کنند. در بطن اکوسیستم هدوپ، Hadoop Distributed File System (HDFS)، MapReduce و Yet Another Resource Negotiator (YARN) قرار دارند. این مولفه ها با هم کار می کنند تا یک پلتفرم مقیاس پذیر و مقاوم در برابر خطا برای پردازش داده های بزرگ ارائه دهند. در ادامه کارایی هر یک از این مولفه ها را مورد بحث قرار می دهیم تا همکاری بین آنها را بتوانید بهتر درک کنید.
ذخیره سازی داده ها در HDFS
HDFS یک سیستم فایل توزیع شده می باشد که برای ذخیره مجموعه داده های بزرگ در چندین ماشین طراحی شده است. داده ها به بلوک ها تقسیم می شوند و در چندین گره داخل خوشه برای افزونگی و تحمل خطا تکرار می شوند. HDFS برای مدیریت فایل های بزرگی طراحی شده است که روی یک گره قرار نمی گیرند. این سیستم برای پردازش داده های بزرگ بسیار ایدهآل و کارآمد می باشد.
پردازش داده ها با MapReduce
MapReduce یک مدل برنامه نویسی است که برای پردازش مجموعه داده های بزرگ به صورت موازی در یک خوشه توزیع شده استفاده می شود. پردازش مجموعه داده های بزرگ را به تکه های کوچک تری تقسیم می کند تا می توانند به صورت موازی در چندین گره داخل خوشه پردازش شوند. این مدل برنامه نویسی، پردازش سریع و کارآمد مجموعه داده های بزرگ را ممکن می سازد.
مدیریت منابع با YARN
YARN یک مدیر منبع است که منابع را در یک خوشه Hadoop مدیریت می کند. یارن اجازه می دهد تا چندین موتور پردازش داده روی یک خوشه کار کنند و منابع را به طور موثر به هر موتور اختصاص دهند. همچنین یک مکان متمرکز برای مدیریت منابع فراهم می کند و مدیریت خوشه های بزرگ هدوپ را آسان تر می سازد.
معماری توزیع شده Hadoop و استفاده از MapReduce و YARN آن را برای پردازش و تجزیه و تحلیل مجموعه داده های بزرگ ایده آل می کند. در بخش بعدی به برخی از کاربرد های کلیدی هدوپ پرداخته ایم.

کاربردهای Hadoop
هدوپ کاربرد های گسترده ای در صنایع مختلف دارد. در اینجا برخی از رایج ترین موارد استفاده از آن آورده شده است:
1- پردازش کلان داده
Hadoop در اصل برای پردازش داده در مقیاس بزرگ طراحی شده بود که آن را برای برنامه های داده های بزرگ ایده آل می کرد. هدوپ با معماری توزیع شده خود می تواند مجموعه داده های بزرگ را به سرعت و کارآمد پردازش کند که همین ویژگی، آن را به گزینه ای محبوب برای برنامه های پردازش داده های بزرگ تبدیل کرده است.
2- انبار داده
توانایی Hadoop برای ذخیره و پردازش مجموعه داده های بزرگ، آن را برای برنامه های ذخیره سازی داده ایده آل می کند. معماری توزیع شده هدوپ و استفاده آن از HDFS، امکان ذخیره و پردازش مقادیر زیادی از داده های ساختار یافته و بدون ساختار را فراهم می سازد.
3- پردازش و تجزیه و تحلیل گزارش
Hadoop می تواند برای تجزیه و تحلیل داده های گزارش از منابع مختلف مانند وب سرور ها، برنامه ها و دستگاه های شبکه استفاده کند. با هدوپ، داده های گزارش را می توان به صورت زنده پردازش، تجزیه و تحلیل کرد. این فریمورک همچنین به سازمان ها اجازه می دهد تا مسائل را به سرعت شناسایی کنند و به آنها پاسخ دهند.
4- یادگیری ماشین
معماری توزیع شده Hadoop و توانایی آن در مدیریت مجموعه داده های بزرگ، این فریمورک را برای برنامه های یادگیری ماشین مناسب می کند. هدوپ می تواند برای آموزش مدل های یادگیری ماشین بر روی مجموعه داده های بزرگ استفاده شود و به سازمان ها این اجازه را بدهد تا بینش هایی به دست آورند و بر اساس داده های خود پیشبینی کنند.
5- اینترنت اشیا (IoT)
Hadoop می تواند برای پردازش، تجزیه و تحلیل داده های دستگاه های IoT استفاده شود. با هدوپ، سازمان ها می توانند مقادیر زیادی از داده های تولید شده توسط دستگاه های IoT را ذخیره و پردازش کنند. این فریمورک همچنین به آنها این امکان را می دهد تا بینش هایی به دست آورند و بر اساس داده های خود تصمیمات بهتری بگیرند.

مزایای Hadoop
هدوپ چندین مزیت را نسبت به سیستم های مدیریت پایگاه داده سنتی ارائه می دهد که در ادامه به آنها می پردازیم:
1- مقیاس پذیری
یکی از مزایای کلیدی مقیاس پذیری است که کاربران را قادر می سازد تا حجم زیادی از داده ها را به سرعت و به صورت کارآمد پردازش کنند.
2- مقرون به صرفه بودن
Hadoop همچنین بسیار مقرون به صرفه می باشد؛ زیرا می تواند بر روی سخت افزار کالا و نرم افزار منبع باز مستقر شود و در نتیجه، نیاز به مجوزهای نرم افزار اختصاصی گران قیمت را کاهش می دهد.
3- کار در صورت ایجاد خطا
علاوه بر این، هدوپ تحمل خطا بالایی دارد؛ به این معنی که حتی در صورت خرابی سخت افزار، می تواند به کار خود ادامه دهد.
4- انعطاف پذیری
انعطاف پذیری یکی دیگر از مزیت های هدوپ می باشد، زیرا می تواند انواع داده ها، از جمله داده های ساختار یافته، بدون ساختار و نیمه ساختار یافته را مدیریت کند. در نهایت، Hadoop دارای ویژگی های امنیتی داخلی است، مانند احراز هویت، مجوز، و رمزگذاری که می تواند از داده ها در برابر دسترسی غیر مجاز و حملات سایبری محافظت کند.
معایب Hadoop
Hadoop با وجود مزایایی که دارد، محدودیت هایی نیز دارد که کاربران باید از آن آگاه باشند:
1- پیچیدگی
یکی از اشکالات اصلی پیچیدگی سیستم آن است که برای راه اندازی و مدیریت به مهارت ها و تخصص های تخصصی نیاز دارید. این امر می تواند منجر به یک منحنی یادگیری شیب دار برای کاربران شود، به ویژه کسانی که در فناوری های کلان داده تازه کار هستند.
2- تاخیر
Hadoop همچنین ممکن است با مشکل تاخیر داشتن مواجه شود، به ویژه در هنگام پردازش داده های بلادرنگ (Real-time).
3- سخت افزار مورد نیاز
در نهایت، سخت افزار مورد نیاز برای هدوپ می تواند بسیار خاص یا کمیاب باشد، به ویژه برای استقرار در مقیاس بزرگ. این الزامات شامل دستگاه های ذخیره سازی با ظرفیت بالا، سرور های متعدد و زیرساخت شبکه پر سرعت است که می تواند به هزینه کلیِ استفاده از Hadoop اضافه کند.

آینده Hadoop
-
روندها و تحولات اخیر
هدوپ به تکامل و انطباق با نیاز های در حال تغییر پردازش داده های بزرگ ادامه می دهد. یکی از روند های اصلی استفاده روزافزون از راه حل های Hadoop مبتنی بر ابر است که در عین کاهش نیاز به سرمایه گذاری های سخت افزاری پرهزینه، انعطاف پذیری و مقیاس پذیری بیشتری را در اختیار کاربران قرار می دهد. علاوه بر این، ابزار ها و فریمورک های جدیدی برای دسترسی بیشتر کاربران غیر فنی به هدوپ در حال توسعه هستند.
-
رقابت با سایر فناوری های کلان داده
در حالی که Hadoop همچنان یک انتخاب محبوب برای پردازش کلان داده به شمار می رود، اما با رقابت فزاینده ای با سایر فناوری ها مانند Apache Spark مواجه است که زمان پردازش سریع تر و رابط برنامه نویسی بصری تری را ارائه می دهد. با این حال، هدوپ همچنان یک راه حل قابل اعتماد و اثبات شده برای سازمان هایی با مجموعه داده های بزرگ و پیچیده می باشد.
-
پتانسیل رشد و نوآوری
در یک جمله، آینده Hadoop بسیار امیدوار کننده است؛ زیرا همچنان به گسترش قابلیت ها و کاربرد های خود در صنایع مختلف ادامه می دهد. با ظهور فناوری های جدید، هدوپ در موقعیت خوبی قرار دارد تا نقش مهمی در پردازش، تجزیه و تحلیل حجم عظیم داده های تولید شده توسط این فناوری ها ایفا کند. به علاوه، اکوسیستم Hadoop به طور مداوم در حال رشد می باشد، با ابزار ها و برنامه های جدید در حال توسعه برای گسترش بیشتر عملکرد و پتانسیل آن.
-
نظرات نهایی در مورد اهمیت Hadoop
Hadoop به دلیل توانایی اش در ذخیره، پردازش، تجزیه و تحلیل حجم عظیمی از داده ها، به یک فناوری ضروری در دنیای داده های بزرگ تبدیل شده است. این انقلاب شیوه مدیریت و تجزیه و تحلیل داده ها را متحول کرده و به سازمان ها اجازه می دهد تا تصمیمات آگاهانه تری بگیرند. از آنجایی که میزان داده ها به طور تصاعدی در حال رشد است، هدوپ یک ابزار حیاتی در زمینه تجزیه و تحلیل داده ها باقی خواهد ماند.
اگر علاقه مند به کسب اطلاعات بیشتر در مورد Hadoop هستید، منابع متعددی از جمله آموزش و مستندات به صورت آنلاین در دسترس هستند. همچنین می توانید با راه اندازی یک خوشه کوچک در دستگاه محلی یا در فضای ابری، هدوپ را برای خودتان امتحان کنید. با به دست آوردن تجربه عملی با این پلتفرم، می توانید توانایی ها و محدودیت هایش و نحوه استفاده از آن برای حل مشکلات دنیای واقعی را بهتر درک کنید.
نتیجه گیری
به طور خلاصه، Hadoop یک پلتفرم محاسباتی توزیع شده منبع باز است که امکان پردازش حجم زیادی از داده ها را فراهم می کند. هدوپ دارای کاربردهای مختلفی از جمله پردازش کلان داده، انبار داده، پردازش و تجزیه و تحلیل گزارش، یادگیری ماشین و اینترنت اشیا می باشد. Hadoop همچنین دارای مزایایی مانند مقیاس پذیری، مقرون به صرفه بودن، تحمل خطا بالا، انعطاف پذیری و امنیت است. با این حال، محدودیت هایی نیز دارد، از جمله پیچیدگی، داشتن تأخیر، منحنی یادگیری و الزامات سخت افزاری.
سوالات متداول
کاربرد اصلی Hadoop چیست؟
از هدوپ در واقع برای پردازش داده های کلان یا همان بیگ دیتا استفاده می شود. Hadoop با توجه به معماری توزیع شده ای که دارد که می تواند داده های حجیم را با سرعت و دقت بالا پردازش کند.
آیا از هدوپ می توان در IoT استفاده کرد؟
بله، می توان از Hadoop برای پردازش و تجزیه و تحلیل داده های دستگاه های IoT استفاده کرد.






دیدگاهتان را بنویسید
برای نوشتن دیدگاه باید وارد بشوید.