
10 انواع الگوریتم های یادگیری ماشین

الگوریتم های یادگیری ماشین برنامه های نرمافزاری هستند که برای کشف الگوهای پنهان در داده ها، پیش بینی و بهبود عملکرد از طریق یادگیری مستقل طراحی شده اند. الگوریتم های مختلف وظایف مختلف یادگیری ماشین را برآورده می کنند. به عنوان مثال، رگرسیون خطی ساده برای مسائل پیش بینی مانند پیش بینی بازار سهام مناسب است، در حالی که الگوریتم KNN برای کارهای طبقه بندی ایده آل خواهد بود. در این مطلب از مجله داناپ، ما یک نمای کلی از الگوریتم های یادگیری ماشین که به طور گسترده شناخته شده و پرکاربرد هستند ارائه خواهیم کرد.
انواع الگوریتم های یادگیری ماشین
الگوریتم های یادگیری ماشینی را می توان به طور کلی به سه نوع طبقه بندی کرد:
- الگوریتم های یادگیری نظارت شده (Supervised Learning Algorithm)
- الگوریتم های یادگیری بدون نظارت (Unsupervised Learning Algorithms)
- الگوریتم های یادگیری تقویتی (Reinforcement Learning algorithm)
نمودار زیر الگوریتم های مختلف ML و دسته بندی های مربوط به آن ها را نشان می دهد:
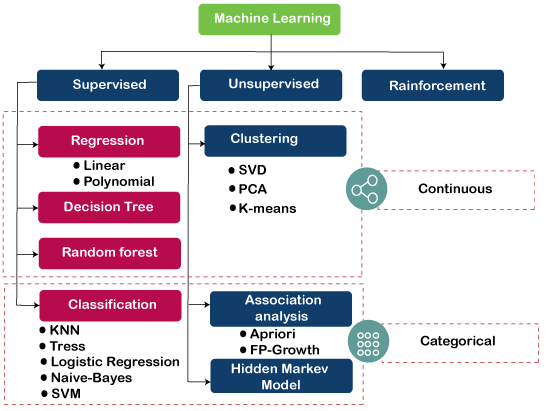
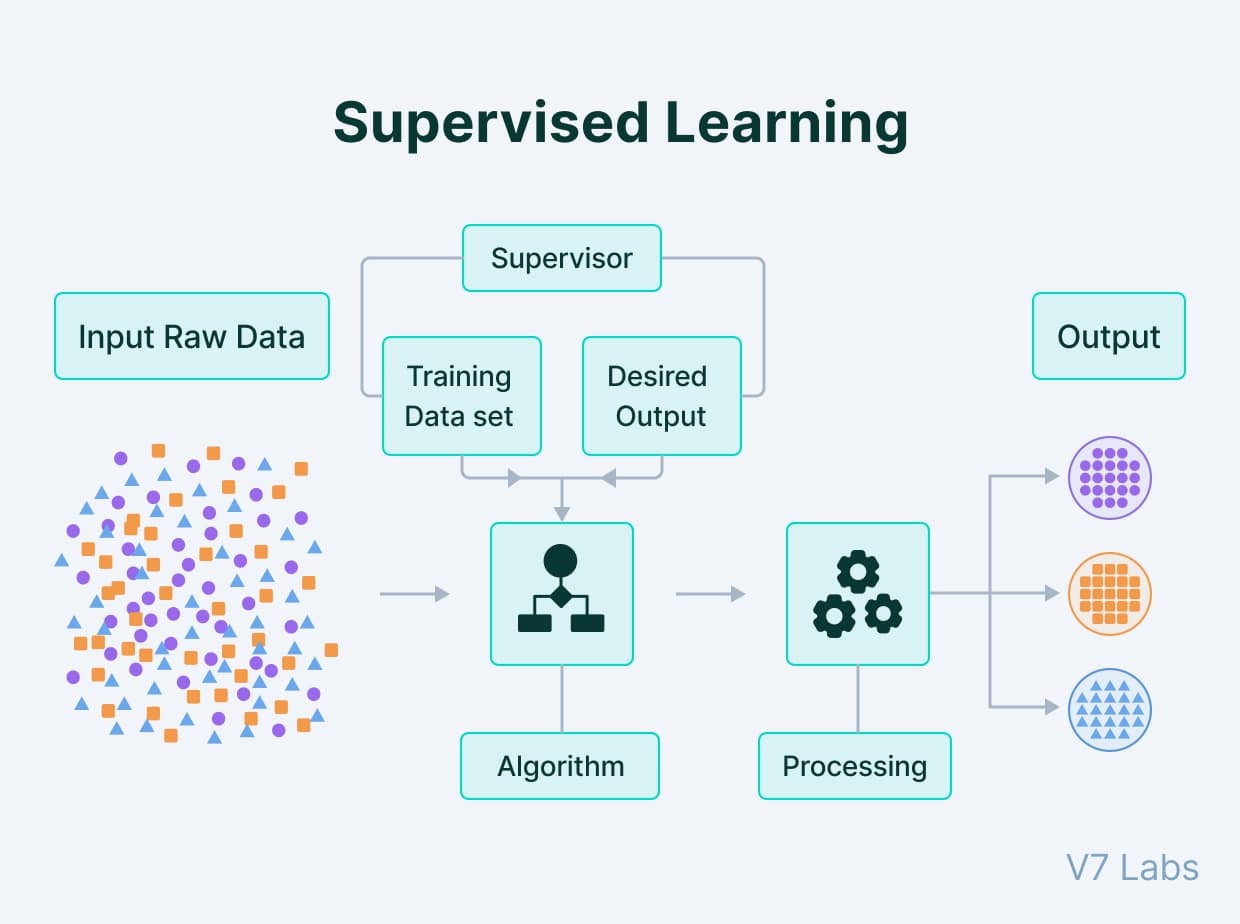
1- الگوریتم های یادگیری نظارت شده (Supervised Learning Algorithm)
یادگیری نظارت شده نوعی از یادگیری ماشینی است که در آن الگوریتم برای یادگیری به راهنمایی خارجی نیاز دارد. مدل ها در یادگیری نظارت شده با استفاده از مجموعه داده های برچسب دار آموزش داده می شوند. پس از تکمیل آموزش و پردازش، مدل با داده های آزمون نمونه آزمایش می شود تا توانایی آن در پیش بینی خروجی های صحیح ارزیابی شود.
یادگیری تحت نظارت را می توان به دو دسته مشکل تقسیم کرد:
- طبقه بندی (Classification): این شامل پیش بینی یک برچسب یا کلاس طبقه بندی شده برای داده های ورودی است. به عنوان مثال می توان به طبقه بندی تصاویر، تجزیه و تحلیل احساسات و تشخیص هرزنامه اشاره کرد.
- رگرسیون (Regression): در این حالت هدف پیش بینی مقدار یا کمیت عددی پیوسته است. از کاربردهای رگرسیون می توان به پیش بینی بازار سهام، تخمین قیمت مسکن و پیش بینی تقاضا اشاره کرد.
الگوریتم های معروف یادگیری تحت نظارت شامل رگرسیون خطی ساده، درخت تصمیم، رگرسیون لجستیک و الگوریتم K-Nearest Neighbors (KNN) هستند.
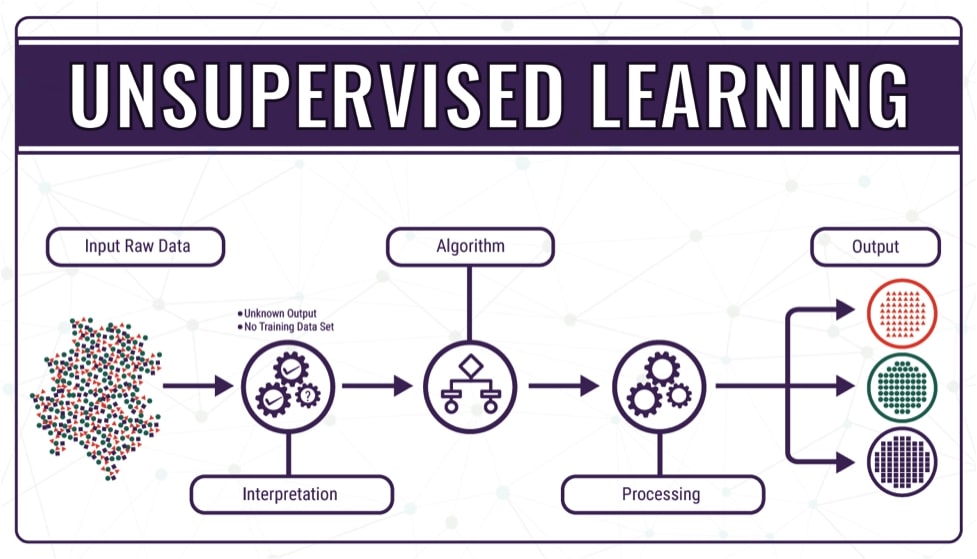
2- الگوریتم های یادگیری بدون نظارت (Unsupervised Learning Algorithms)
یادگیری بدون نظارت نوعی یادگیری ماشینی است که در آن الگوریتم از داده ها بدون هیچ نظارت خارجی یاد می گیرد. در این حالت، مدل ها با استفاده از مجموعه داده های بدون برچسب که دسته بندی یا طبق هبندی نشده اند، آموزش داده می شوند. سپس الگوریتم باید بر روی این داده ها بدون هیچ راهنمایی یا خروجی از پیش تعریف شده عمل کند. هدف یادگیری بدون نظارت، کشف بینش معنادار از مقادیر زیادی داده است.
یادگیری بدون نظارت را می توان به دو نوع طبقه بندی کرد:
- خوشه بندی (Clustering): این شامل گروه بندی نقاط داده مشابه بر اساس ویژگی ها یا الگوهای ذاتی آنها است. الگوریتم های خوشه بندی به شناسایی خوشه ها یا بخش های طبیعی در داده ها کمک می کنند.
- قواعد انجمنی (Association): یادگیری انجمنی بر شناسایی روابط یا ارتباط بین آیتم ها یا متغیرهای مختلف در یک مجموعه داده متمرکز است. این به کشف الگوهایی مانند مجموعه آیتمها یا قوانین مکرر کمک میکند.
الگوریتم های یادگیری ماشین بدون نظارت شامل K-means Clustering، Apriori Algorithm و Eclat هستند.
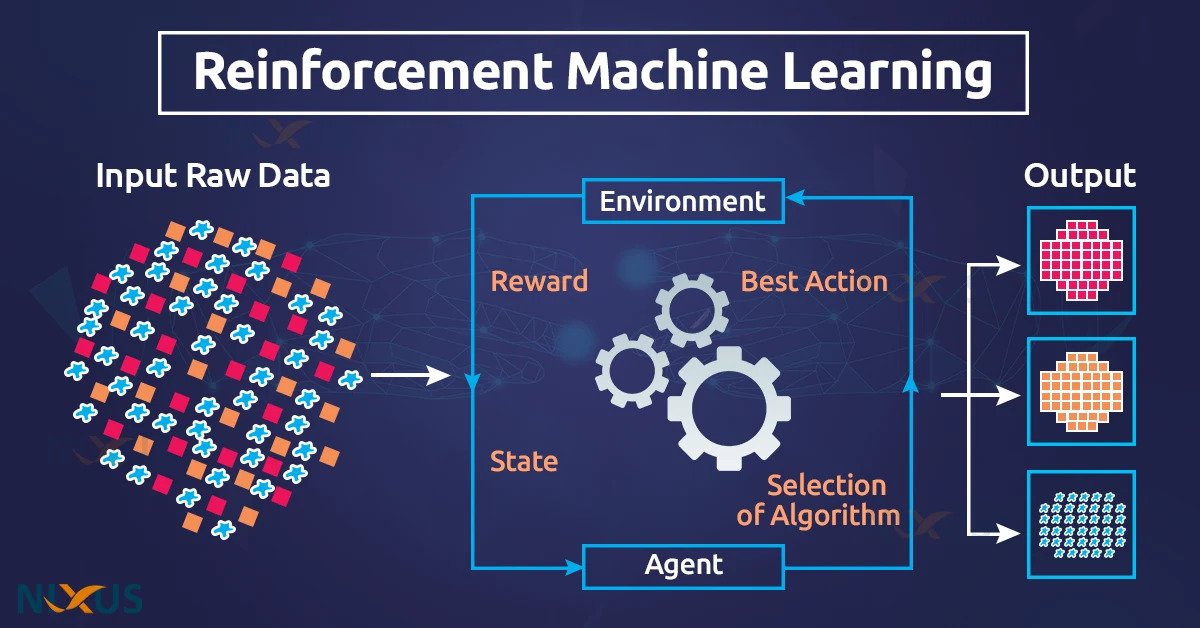
3- الگوریتم های یادگیری تقویتی (Reinforcement Learning algorithm)
یادگیری تقویتی شامل تعامل یک عامل با محیط خود، انجام اقدامات و یادگیری از طریق بازخورد است. در این نوع یادگیری، عامل بازخوردی را در قالب پاداش دریافت می کند. پاداش مثبت برای اعمال خوب و پاداش منفی برای اعمال بد داده می شود. برخلاف یادگیری تحت نظارت و بدون نظارت، یادگیری تقویتی نظارت مستقیمی برای عامل ایجاد نمی کند.
هدف اصلی یادگیری تقویتی بهینه سازی رفتار عامل برای به حداکثر رساندن پاداش های تجمعی در طول زمان است. عامل از طریق آزمون و خطا، کاوش در اعمال مختلف و مشاهده پیامدهای آن اعمال در محیط یاد می گیرد.
یکی از الگوریتم های محبوب مورد استفاده در یادگیری تقویتی Q-Learning است. Q-Learning به طور گسترده در حوزه های مختلف، از جمله رباتیک، بازی کردن و سیستم های مستقل استفاده می شود.
فهرست الگوریتم های معروف یادگیری ماشینی
فهرست معروف ترین الگوریتم های یادگیری ماشین به صورت زیر است:
- الگوریتم رگرسیون خطی (Linear Regression Algorithm)
- الگوریتم رگرسیون لجستیک (Logistic Regression Algorithm)
- درخت تصمیم (Decision Tree)
- SVM
- بیز ساده (Naïve Bayes)
- KNN
- خوشه بندی K-Means
- جنگل تصادفی (Random Forest)
- Apriori
- PCA
در ادامه با هر کدام یک از این الگوریتم های ماشین لرنینگ به صورت مختصر آشنا خواهیم شد.
1- الگوریتم رگرسیون خطی
رگرسیون خطی یک الگوریتم یادگیری ماشینی است که به طور گسترده استفاده می شود و برای تجزیه و تحلیل پیش بینی مورد استفاده قرار می گیرد. در درجه اول برای پیش بینی مقادیر عددی پیوسته مانند حقوق، سن و غیره استفاده می شود.
رگرسیون خطی رابطه خطی بین متغیر وابسته و یک یا چند متغیر مستقل را ایجاد می کند. این الگوریتم نشان می دهد که چگونه متغیر وابسته (y) در پاسخ به تغییرات متغیر (های) مستقل (x) تغییر می کند. هدف رگرسیون خطی یافتن بهترین خطی خواهد بود که رابطه بین متغیرها را نشان می دهد. این خط به خط رگرسیون معروف است.
معادله خط رگرسیون به صورت زیر است:
y = a0 + a * x + b
- در اینجا، y نشان دهنده متغیر وابسته است.
- x نشان دهنده متغیر مستقل است.
- a0 نقطه قطع خط است.
رگرسیون خطی را می توان بیشتر به دو نوع طبقه بندی کرد:
- رگرسیون خطی ساده: در رگرسیون خطی ساده از یک متغیر مستقل برای پیش بینی مقدار متغیر وابسته استفاده می شود.
- رگرسیون خطی چندگانه: در رگرسیون خطی چندگانه، از بیش از یک متغیر مستقل برای پیشبینی مقدار متغیر وابسته استفاده میشود.
نمودار زیر نمونه ای از رگرسیون خطی را برای پیش بینی وزن بر اساس قد نشان می دهد.
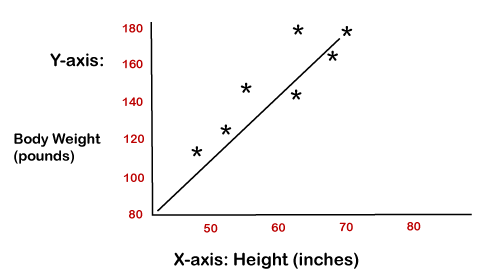
2- الگوریتم رگرسیون لجستیک
رگرسیون لجستیک یک الگوریتم یادگیری نظارت شده است که برای پیشبینی متغیرهای مقولهای یا گسسته استفاده می شود. این الگوریتم معمولاً برای مسائل طبقه بندی در یادگیری ماشین مورد استفاده قرار می گیرد، جایی که خروجی الگوریتم رگرسیون لجستیک می تواند باینری باشد، مانند بله یا خیر، 0 یا 1، قرمز یا آبی و غیره.
رگرسیون لجستیک شباهت هایی با رگرسیون خطی دارد، اما در کاربرد آنها متفاوت است. در حالی که رگرسیون خطی برای مسائل رگرسیون برای پیشبینی مقادیر پیوسته استفاده می شود، رگرسیون لجستیک برای مسائل طبقه بندی برای پیش بینی مقادیر گسسته استفاده می شود.
3- الگوریتم درخت تصمیم
الگوریتم درخت تصمیم یکی دیگر از الگوریتم های یادگیری ماشین و یک روش یادگیری نظارت شده است که در درجه اول برای حل مسائل طبقه بندی استفاده می شود، اگرچه می توان آن را برای مسائل رگرسیونی نیز به کار برد. همه کاره است و می تواند متغیرهای طبقه ای و پیوسته را مدیریت کند. الگوریتم داده ها را در یک ساختار درخت مانند شامل گره ها و شاخه ها نشان می دهد. این فرآیند با یک گره ریشه شروع می شود و با شاخه هایی که به گره های بعدی منتهی می شود گسترش می یابد و در نهایت به گره های برگ می رسد که نتایج یا پیش بینی های نهایی را ارائه می دهند.
در درخت تصمیم، گره های داخلی ویژگی های مجموعه داده را نشان میدهند، شاخه ها قوانین تصمیم گیری را بر اساس آن ویژگی ها نشان داده و گره های برگ نتایج یا پیشبینی های نهایی را نشان می دهند.
درخت های تصمیم گیری کاربردهای مختلفی در دنیای واقعی دارند، مانند تشخیص سلول های سرطانی و غیر سرطانی، ارائه توصیه های خرید به مشتریان و غیره. آنها به ویژه در سناریوهایی که تفسیر پذیری و توضیح پذیری فرآیند تصمیم گیری ضروری است مفید هستند.
4- الگوریتم ماشین بردار پشتیبان
ماشین بردار پشتیبان (SVM) یک الگوریتم یادگیری نظارت شده است که معمولاً برای کارهای طبقه بندی استفاده می شود، اگرچه می تواند برای مشکلات رگرسیون نیز اعمال شود. هدف Support Vector Machine ایجاد یک ابر صفحه یا مرز تصمیم بهینه است که به طور موثر نقاط داده را به کلاس های مختلف جدا می کند.
مفهوم کلیدی در SVM، شناسایی بردارهای پشتیبان است که نقاط داده ای هستند که به تعریف هایپرپلین کمک می کنند. این الگوریتم به دنبال به حداکثر رساندن حاشیه بین بردارهای پشتیبان کلاس های مختلف است که در نتیجه یک مرز طبقه بندی موثر ایجاد می شود.
SVM در سناریوهای مختلفی، از جمله تشخیص چهره، طبقه بندی تصویر، کشف دارو و موارد دیگر کاربرد پیدا می کند. این الگوریتم به ویژه در هنگام برخورد با مجموعه داده های با ابعاد بالا مفید است.
نمودار زیر را به عنوان نمونه در نظر بگیرید:
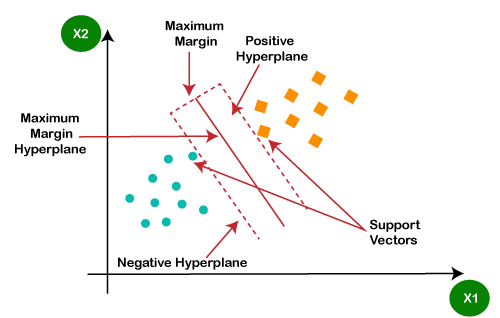
همانطور که در نمودار بالا می بینیم، hyperplane مجموعه داده ها را به دو کلاس مختلف طبقه بندی کرده است.
5- الگوریتم ساده بیز
الگوریتم Naïve Bayes یکی دیگر از الگوریتم های یادگیری ماشین نظارت شده است که برای پیش بینی بر اساس احتمال یک شی متعلق به یک کلاس خاص استفاده می شود. این الگوریتم نام خود را از کاربرد قضیه بیز گرفته است و با این فرض ساده عمل می کند که متغیرها مستقل از یکدیگر هستند.
قضیه بیز بر مفهوم احتمال شرطی استوار است که احتمال وقوع رویداد A را با توجه به اینکه رویداد B قبلاً رخ داده است، محاسبه می کند. معادله قضیه بیز به صورت زیر است:
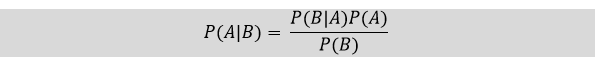
طبقه بندی کننده ساده بیز یکی از طبقه بندی کننده های برتر در نظر گرفته می شود که نتایج قابل اعتمادی را برای حوزه های مختلف مشکل ارائه می دهد. ساختار آن ساده و به ویژه برای مجموعه داده های بزرگ مناسب است. Naïve Bayes معمولاً برای کارهای طبقه بندی متن، مانند فیلتر کردن هرزنامه یا تجزیه و تحلیل احساسات استفاده می شود.
6- K-نزدیک ترین همسایگان (KNN)
K-Nearest Neighbors (KNN) یک الگوریتم یادگیری نظارت شده است که می تواند برای مسائل طبقه بندی و رگرسیون اعمال شود. این الگوریتم با فرض شباهت بین یک نقطه داده جدید و نقاط داده موجود عمل می کند. بر اساس این شباهت ها، الگوریتم نقطه داده جدید را به مشابه ترین دسته اختصاص می دهد یا مقدار آن را برای رگرسیون پیش بینی می کند.
KNN اغلب به عنوان یک الگوریتم یادگیرنده تنبل شناخته می شود زیرا تمام داده های آموزشی موجود را حفظ می کند و موارد جدید را بر اساس نزدیکی آنها به K نزدیکترین همسایه طبقه بندی می کند. این الگوریتم بسته به نیازهای خاص، فاصله بین نقاط داده را با استفاده از یک تابع فاصله، مانند فاصله اقلیدسی، مینکوفسکی، منهتن یا همینگ اندازه گیری می کند. KNN یک الگوریتم همه کاره است و می تواند در حوزه های مختلفی مانند تشخیص تصویر، سیستم های توصیه گیر و تشخیص ناهنجاری موثر باشد.
7- خوشه بندی K-Means
خوشه بندی K-means یکی دیگر از الگوریتم های یادگیری ماشین بدون نظارت است که برای حل مسائل خوشه بندی استفاده می شود. این الگوریتم شامل گروه بندی مجموعه داده ها به K خوشه های مختلف بر اساس شباهت ها و تفاوت های آن ها است. این به این معنی است که مجموعه دادههایی با بیشترین شباهت در یک خوشه با هم گروهبندی میشوند، در حالی که شباهتهای حداقلی با سایر خوشهها ندارند. در K-means، مقدار K تعداد خوشهها را نشان میدهد و «میانگین» به فرآیند میانگینگیری مجموعه داده برای شناسایی مرکزها اشاره دارد.
الگوریتم با تخصیص مکرر نقاط داده به نزدیکترین مرکز و محاسبه مجدد مرکزها بر اساس میانگین نقاط اختصاص داده شده عمل می کند. این روند تا زمانی ادامه می یابد که مرکزها تثبیت و خوشه ها بهینه شوند. خوشه بندی K-means به طور گسترده در برنامه های مختلف از جمله تقسیم بندی مشتری، فشرده سازی تصویر و تشخیص ناهنجاری استفاده می شود.
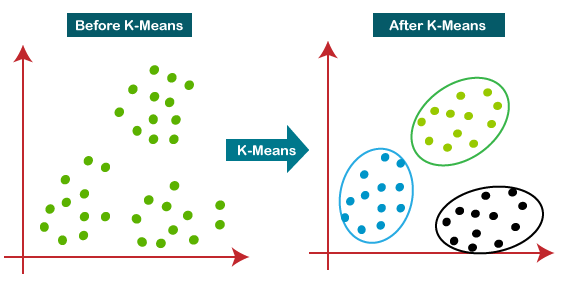
8- الگوریتم جنگل تصادفی
جنگل تصادفی یک الگوریتم یادگیری نظارت شده و یکی از کاربردی ترین الگوریتم های یادگیری ماشین به حساب می آید که قادر به حل مسائل طبقه بندی و رگرسیون در یادگیری ماشین است. این الگوریتم به خانواده یادگیری گروهی تعلق دارد و از قدرت طبقه بندی کنندههای متعدد برای افزایش عملکرد مدل استفاده می کند.
این الگوریتم از مجموعه ای از درختان تصمیم تشکیل شده است که هر درخت بر روی زیرمجموعه ای از مجموعه داده داده شده آموزش داده شده است. سپس پیش بینی های درختان جداگانه برای بهبود دقت پیش بینی کلی مدل ترکیب می شوند. به طور معمول، یک جنگل تصادفی دارای تعداد کافی درخت است که از 64 تا 128 درخت متغیر است، زیرا تعداد بیشتر درختان منجر به دقت بالاتر می شود.
یکی از مزایای قابل توجه الگوریتم جنگل تصادفی، کارایی آن در مدیریت داده های گم شده و نادرست است. این الگوریتم می تواند به طور کارآمد مجموعه داده هایی را با چنین نقص هایی پردازش کرده و آن را به یک انتخاب قوی برای برنامه های مختلف در دنیای واقعی تبدیل کند.
جنگل تصادفی هم سرعت و هم دقت را ارائه میدهد و آن را به انتخابی محبوب در میان متخصصان یادگیری ماشین تبدیل میکند. این به طور گسترده ای در حوزه های مختلف، از جمله امور مالی، مراقبت های بهداشتی و تشخیص تصویر استفاده می شود.
9- الگوریتم Apriori
الگوریتم Apriori یک الگوریتم یادگیری بدون نظارت است که برای حل مسائل مرتبط استفاده می شود. این الگوریتم با استفاده از مجموعه آیتم های مکرر برای تولید قوانین مرتبط عمل میکند و به طور خاص برای پایگاههای دادهای که حاوی دادههای تراکنش هستند طراحی شده است. با استفاده از قوانین انجمنی، الگوریتم می تواند قدرت یا ضعف ارتباط بین دو شی را تعیین کند. محاسبه کارآمد مجموعه اقلام از طریق استفاده از جستجوی وسعت اول و درخت هش به دست می آید.
این الگوریتم یک فرآیند تکراری را برای کشف مجموعه آیتم های مکرر از مجموعه داده های بزرگ دنبال می کند. با شناسایی اقلام فردی مکرر شروع می شود و به تدریج جستجو را به مجموعه آیتم های بزرگتر با در نظر گرفتن زیرمجموعه های مجموعه آیتم های مکرر کشف شده قبلی گسترش می دهد.
الگوریتم Apriori توسط R. Agrawal و Srikant در سال 1994 پیشنهاد شد. این الگوریتم کاربرد گسترده ای در تجزیه و تحلیل سبد بازار پیدا می کند و به درک اینکه کدام محصولات اغلب با هم خریداری می شوند کمک می کند. علاوه بر این، می توان از آن در زمینه مراقبت های بهداشتی برای شناسایی واکنش های دارویی بالقوه در بیماران استفاده کرد.
با استفاده از الگوریتم Apriori، میتوان بینشهای ارزشمندی را از دادههای تراکنش استخراج کرد و به کسبو کار ها و صنایع در تصمیم گیری آگاهانه و افزایش تجربه مشتری کمک کرد.
10- تجزیه و تحلیل اجزای اصلی (PCA)
تجزیه و تحلیل اجزای اصلی (Principle Component Analysis) آخرین الگوریتم در فهرست الگوریتم های یادگیری ماشین و نوعی تکنیک یادگیری بدون نظارت است که برای کاهش ابعاد استفاده می شود. هدف اصلی آن کاهش تعداد ویژگی هایی در یک مجموعه داده است که امکان دارد به شدت با یکدیگر مرتبط باشند. PCA از یک فرآیند آماری استفاده می کند که مشاهدات ویژگی های همبسته را از طریق تبدیل متعامد به مجموعه ای از ویژگی های خطی نامرتبط تبدیل خواهد کرد. این تکنیک به طور گسترده برای تجزیه و تحلیل داده های اکتشافی و مدل سازی پیش بینی استفاده می شود.
نتیجه گیری
الگوریتم های یادگیری ماشین نقش مهمی در استخراج بینش های معنادار و پیش بینی از داده ها دارند. آن ها را می توان بر اساس رویکردهای یادگیری به انواع مختلفی دسته بندی کرد، یعنی یادگیری تحت نظارت، یادگیری بدون نظارت و یادگیری تقویتی. الگوریتم های یادگیری ماشین ابزارهای قدرتمندی برای تجزیه و تحلیل دادهها، پیش بینی و تصمیم گیری فراهم می کنند که به پیشرفت در حوزه های متعدد و ایجاد نوآوری در صنایع مختلف کمک می کند. در این مطلب انواع الگوریتم های ماشین لرنینگ به همراه معرفی مختصر آن معرفی شدند، به امید اینکه این مطلب برای شما مفید بوده باشد.
سوالات متداول
الگوریتم های یادگیری ماشین به چند دسته تقسیم می شوند؟
به طور کلی این الگوریتم ها به 3 دسته یادگیری نظارت شده، یادگیری بدون نظارت و یادگیری تقویتی تقسیم می شوند.
از الگوریتم رگرسیون خطی با چه هدفی استفاده می شود؟
از این الگوریتم برای تجزیه و تحلیل پیش بینی استفاده می شود. در واقع رگرسیون خطی رابطه ای میان متغیر وابسته و یک یا چند متغیر مستقل دیگر را ایجاد می کند.







دیدگاهتان را بنویسید
برای نوشتن دیدگاه باید وارد بشوید.